Tutorial 1: An introduction to sheap, basic usage, and some of its capabilities
sheap is a Python package designed to fit and estimate the posterior parameters of Active Galactic Nuclei (AGN) spectra. It is built on top of JAX, enabling GPU-accelerated computations for efficient spectral analysis.
from jax import config
config.update("jax_enable_x64", True)
from pathlib import Path
import glob
Throughout this notebook, we will introduce the basic features of sheap and demonstrate its usage through practical examples.
import sheap
from sheap import Sheapectral
from sheap.Utils.SpectralReaders import parallel_reader
Sheapectral is a class that allows the user to read and handle spectra for the analysis process.
As a companion tool, we provide parallel_reader, a utility designed to efficiently read a set of SDSS FITS spectra in parallel. It returns the object coordinates (coords) together with the spectra arranged in channels:
Channel 0 — Wavelength
Channel 1 — Flux
Channel 2 — Error
Channel 3 (optional) — Velocity distribution (if available)
This structure makes it straightforward to handle large batches of spectra for further processing in SHEAP.
spectrum_dic = Path(sheap.__file__).resolve().parent / "SuportData" / "Spectra"
files = sorted(glob.glob(f"{spectrum_dic}/*.fits"))
coords,_,spectra = parallel_reader(files,function="fits_reader_sdss")
z = [0.184366,0.161769]
files
['/Users/felavila/Work/MyPackages/sheap_update2/sheap/SuportData/Spectra/11109-58523-0450.fits',
'/Users/felavila/Work/MyPackages/sheap_update2/sheap/SuportData/Spectra/8222-57431-0561.fits']
We instantiate the Sheapectral class, passing the spectrum, the object’s redshift (z), and sky coordinates (coords) so it can apply Galactic reddening automatically.
If z is None, the spectrum is treated as already in the rest frame.
If your input spectrum is already dereddened, set extinction_correction=False to skip correction.
Next you can call Sheapectral.fitmodel() and Sheapectral.plot().
spec_class = Sheapectral(spectra,z=z,coords=coords,names = [f"spectra_{i}" for i in range(2)])
extinction correction will be do it, change 'extinction_correction' to done if you want to avoid this step
/Users/felavila/Work/MyPackages/sheap_update2/.venv/lib/python3.11/site-packages/jax/_src/ops/scatter.py:92: FutureWarning: scatter inputs have incompatible types: cannot safely cast value from dtype=float64 to dtype=float32 with jax_numpy_dtype_promotion='standard'. In future JAX releases this will result in an error.
warnings.warn(
redshift correction will be do it, change 'redshift_correction' to done if you want to avoid this step
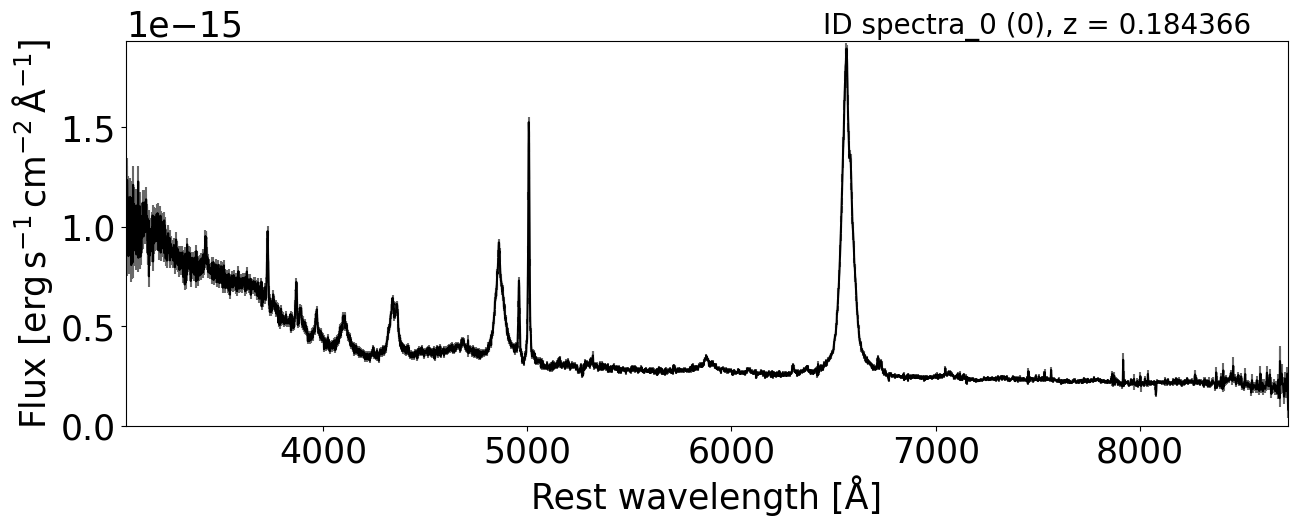
To view the full spectrum, users can access the quicklook property.
This displays the object’s spectrum with its ID or name in the top-left corner.
In parentheses, it also shows the object’s position within the spectra and its redshift.
spec_class.quicklook(0)
<Axes: xlabel='Rest wavelength [Å]', ylabel='Flux [$\\mathrm{erg\\,s^{-1}\\,cm^{-2}\\,\\AA^{-1}}$]'>
To fit the spectra first call the instance method makemodel on the spec_class, which initializes the SheapModelBuilder class. This class loads YAMLs files that contain most known emission lines and creates a SheapModel instance with all relevant information about the lines and fit regions. It forms the foundation of the fitting process and includes several key parameters:
The tuple (
xmin,xmax): wavelength limits for searching emission lines.n_broadandn_narrow: number of broad and narrow componentscontinuum_profile: continuum model to use; sheap supports['linear', 'powerlaw', 'brokenpowerlaw', 'logparabola', 'exp_cutoff', 'polynomial']fe_mode: method for estimating the iron contribution; accepted values are'none','model', and'template'
In the first example, we fit the Hα region (typically 6000–7200 Å) with a linear continuum profile and no iron contribution.
spec_class.makemodel((6000,7200),n_broad=1,n_narrow=1,fe_mode ="None",continuum_profile="brokenpowerlaw",verbose=True,add_balmer_continuum = False ,add_balmerhighorder_continuum = False)
spec_class.modelbuild.sheapmodel
SheapModel(lines=[SpectralLine(line_name='broad1', center=[6046.44, 7002.23, 6562.82, 6678.2, 7065.196], region='broad', component=1, subregion=[None, None, None, None, None], amplitude=[1.0, 1.0, 1.0, 1.0, 1.0], element=['Oxygen', 'Oxygen', 'Hydrogen', 'Helium', 'Helium'], profile='SPAF', region_lines=['OIa', 'OIb', 'Halpha', 'HeIf', 'HeIg'], amplitude_relations=[(0, 1.0, 0), (1, 1.0, 1), (2, 1.0, 2), (3, 1.0, 3), (4, 1.0, 4)], subprofile=None, rarity=None, template_info=None), SpectralLine(line_name='brokenpowerlaw', center=None, region='continuum', component=0, subregion=None, amplitude=None, element=None, profile='brokenpowerlaw', region_lines=None, amplitude_relations=None, subprofile=None, rarity=None, template_info=None), SpectralLine(line_name='narrow1', center=[6562.82, 6678.2, 7065.196, 6300.304, 6363.776, 6548.05, 6583.46, 6716.44, 6730.81], region='narrow', component=1, subregion=[None, None, None, None, None, None, None, None, None], amplitude=[1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0], element=['Hydrogen', 'Helium', 'Helium', 'Oxygen', 'Oxygen', 'Nitrogen', 'Nitrogen', 'Sulfur', 'Sulfur'], profile='SPAF', region_lines=['Halpha', 'HeIf', 'HeIg', 'OIa', 'OIb', 'NIIa', 'NIIb', 'SIIa', 'SIIb'], amplitude_relations=[(0, 1.0, 0), (1, 1.0, 1), (2, 1.0, 2), (3, 1.0, 3), (4, 1.0, 4), (5, 0.3, 6), (6, 1.0, 6), (7, 1.0, 7), (8, 1.0, 8)], subprofile=None, rarity=None, template_info=None)], profile_functions=[], profile_names=[], params_dict={}, profile_params_index_list=[], params=None, uncertainty_params=None, original_idx=[0, 1, 2], _master_param_names=[], global_profile_params_index_list=[])
When the region is already defined, we can call another important instance method of the class—.fitmodel()—which invokes the fitting process implemented in the SheapModelFitting class.
Its main parameters are:
list_num_steps=[1_000]: a list containing the number of iterations to perform.list_learning_rate=[1e-2]: a list containing the learning rates to try.run_uncertainty_params=False: whether to run the uncertainty estimation (we’ll compute uncertainties later).add_penalty_function=False: whether to include a penalty function in the loss.penalty_weight=0.01: weight applied to the penalty function.curvature_weight=1e3: weight applied to the curvature regularization term.smoothness_weight=1e5: weight applied to the smoothness regularization term.max_weight=0.1: maximum weight scaling factor for constraints.
By default, these values are pre-set to reasonable choices but can be changed depending on the needs of the user and the complexity of the spectra being fitted.
In this example, we disable uncertainty estimation (run_uncertainty_params=False) and compute uncertainties in a separate step. Note that list_num_steps and list_learning_rate must have the same length, since each entry in list_learning_rate is paired with the corresponding number of steps in list_num_steps.
spec_class.fitmodel(list_num_steps=[1_000],list_learning_rate=[1e-2])
Fitting 2 spectra with 4590 wavelength pixels
========================================
STEP1 (step1) params to minimize 21
learning_rate: 0.01 num_steps: 1000 non_optimize_in_axis: 4
Time for step 'step1': 0.85 seconds
The entire process took 0.85 (0.43s by spectra)
After fitting, you can visualize the results by calling:
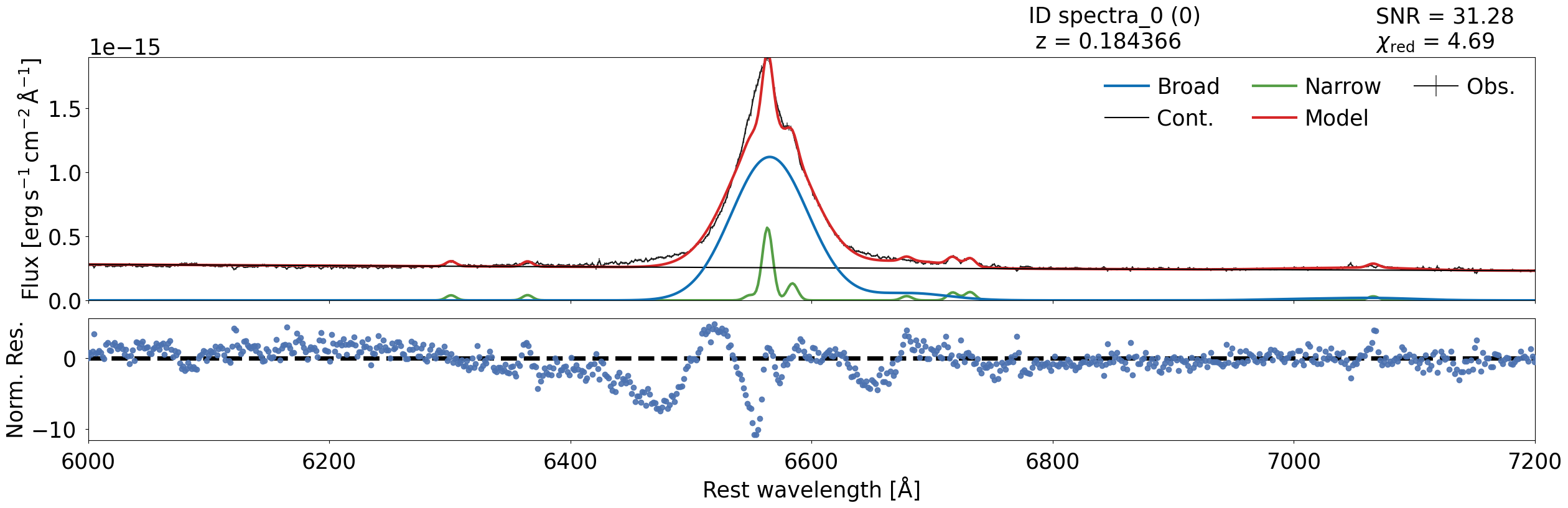
spec_class.modelplot.plot()
spec_class.modelplot.plot(0)
spec_class.modelplot.plot(1)
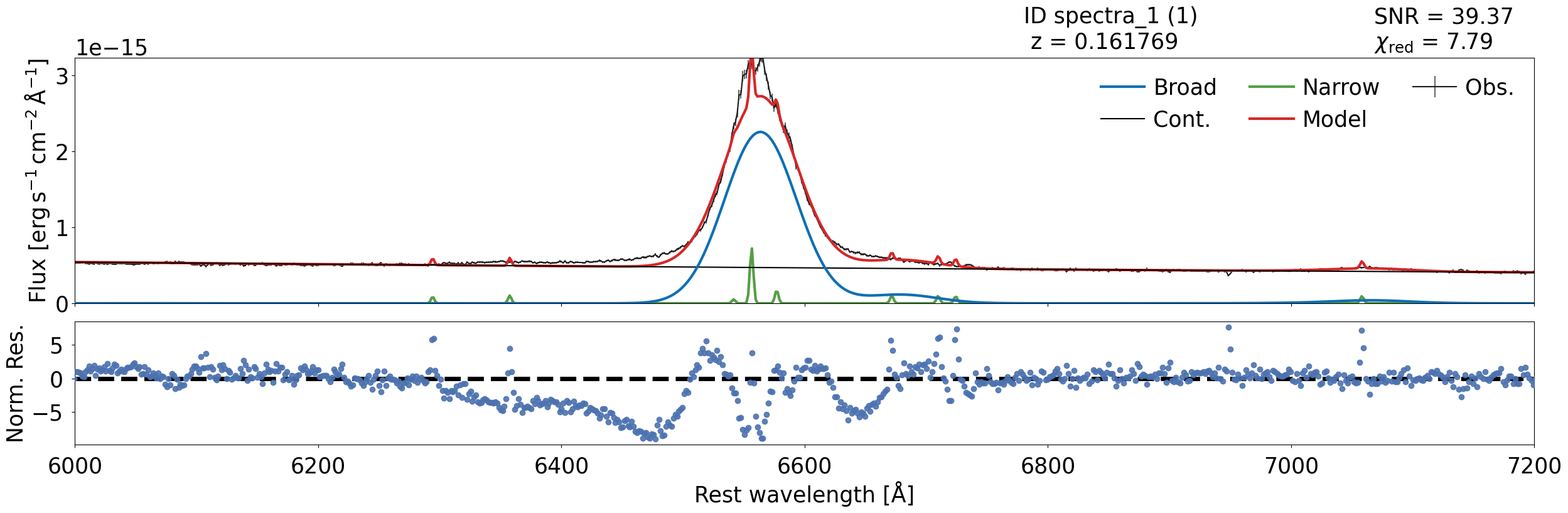
It is easy to see that the fit is not perfect — the poor fit occurs because it requires more components to be fitted effectively.
We will see how to improve the fitting in the next notebooks.
Finally, we will show the instance estimate_posteriors, which uses the MasterSampler class.
Currently, sheap can handle several types of posterior-parameter estimation:
The Monte Carlo method
The pseudo Monte Carlo method
The covariance matrix method
MCMC powered by the NumPyro package
sheap can also summarize the samples and estimate posterior parameters such as luminosity, supermassive black hole mass, among others.
spec_class.estimate_posteriors(sampling_method="montecarlo",summarize=False,overwrite=True)
Running Monte Carlo with JAX.,sample over the spectra using init params
Sampling obj: 0%| | 0/50 [00:00<?, ?it/s]
Sampling obj: 100%|██████████| 50/50 [00:34<00:00, 1.43it/s, it_s=0.0003]
Getting posterior-params: 100%|██████████| 2/2 [00:00<00:00, 11.23it/s]
spec_class.result.posterior["montecarlo"]["posterior_result"]["spectra_1"].keys()
dict_keys(['basic_params', 'L_w', 'L_bol', 'F_cont', 'distances', 'extra_params', 'samples_phys'])
To study the results, the easiest approach is to use the result property of the spec_class object. This returns a SheapResult instance that contains the region, parameter results, and, most importantly, the posterior. The posterior is represented as a dictionary where the keys are the method use to estimate the uncertainties: then inside this you have the posterior result, num_samples, key_seed.
Then posterior result contains all the line information, organized by the names specified by the user when initializing the code—in this case, ['spectra_0', 'spectra_1'].
When we inspect the resulting dictionary in detail, it contains the following keys:
TODO: update the params that can be calculate and how to take it.
basic_params: Values for the individual lines in the fit. Since SHEAP groups lines into “templates” that share shift and FWHM,basic_paramsseparates these lines for detailed analysis.L_wandL_bol: The luminosity at a specific wavelength (L_w) and the bolometric luminosity (L_bol).extras_params: Additional parameters for each line. For example, for Hα it includes:L_wL_bolfwhm_kmslog10_smbhLeddmdot_msun_per_year
params_dict_values: The fitted parameters and their posterior distributions. Note that these parameters remain combined, so their keys follow the patternnameparam_linename_region. For combined lines,linename = region + component.
Finally, to save your results, call the save_to_pickle method on the instance.
spec_class.save_to_pickle("dic1.pkl")
Estimated pickle size: 168.64 KB
To load saved results for further testing or new models, use the from_pickle class method:
new_instance = Sheapectral.from_pickle('path/to/your_saved_results.pkl')
spec_class_readed = Sheapectral.from_pickle("dic1.pkl")
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
Cell In[15], line 1
----> 1 spec_class_readed = Sheapectral.from_pickle("dic1.pkl")
File ~/work/MyPackages/sheap/sheap/MainSheap/Sheapectral.py:492, in Sheapectral.from_pickle(cls, filepath)
478 """
479 Load a saved Sheapectral instance from a pickle file.
480
(...) 489 Restored object with loaded spectra and results.
490 """
491 filepath = Path(filepath)
--> 492 with open(filepath, "rb") as f:
493 data = pickle.load(f)
495 obj = cls(
496 spectra=data["spectra"],
497 z=data["z"],
(...) 501 redshift_correction=data["redshift_correction"],
502 )
FileNotFoundError: [Errno 2] No such file or directory: 'dic1.pkl'
To reproduce the same plot, simply call the modelplot.plot() method again:
spec_class_readed._fit_instance.modelplot.plot()
# spec_class.result.posterior[1]["basic_params"]["broad"]["luminosity"]
End tutorial 1.